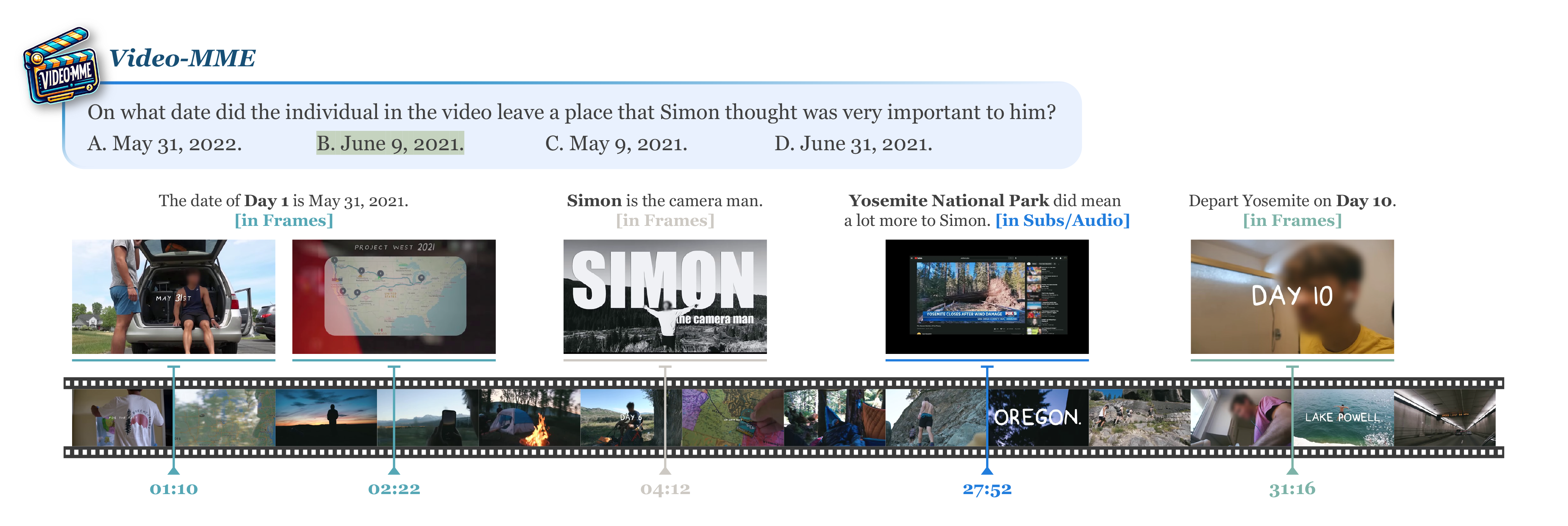
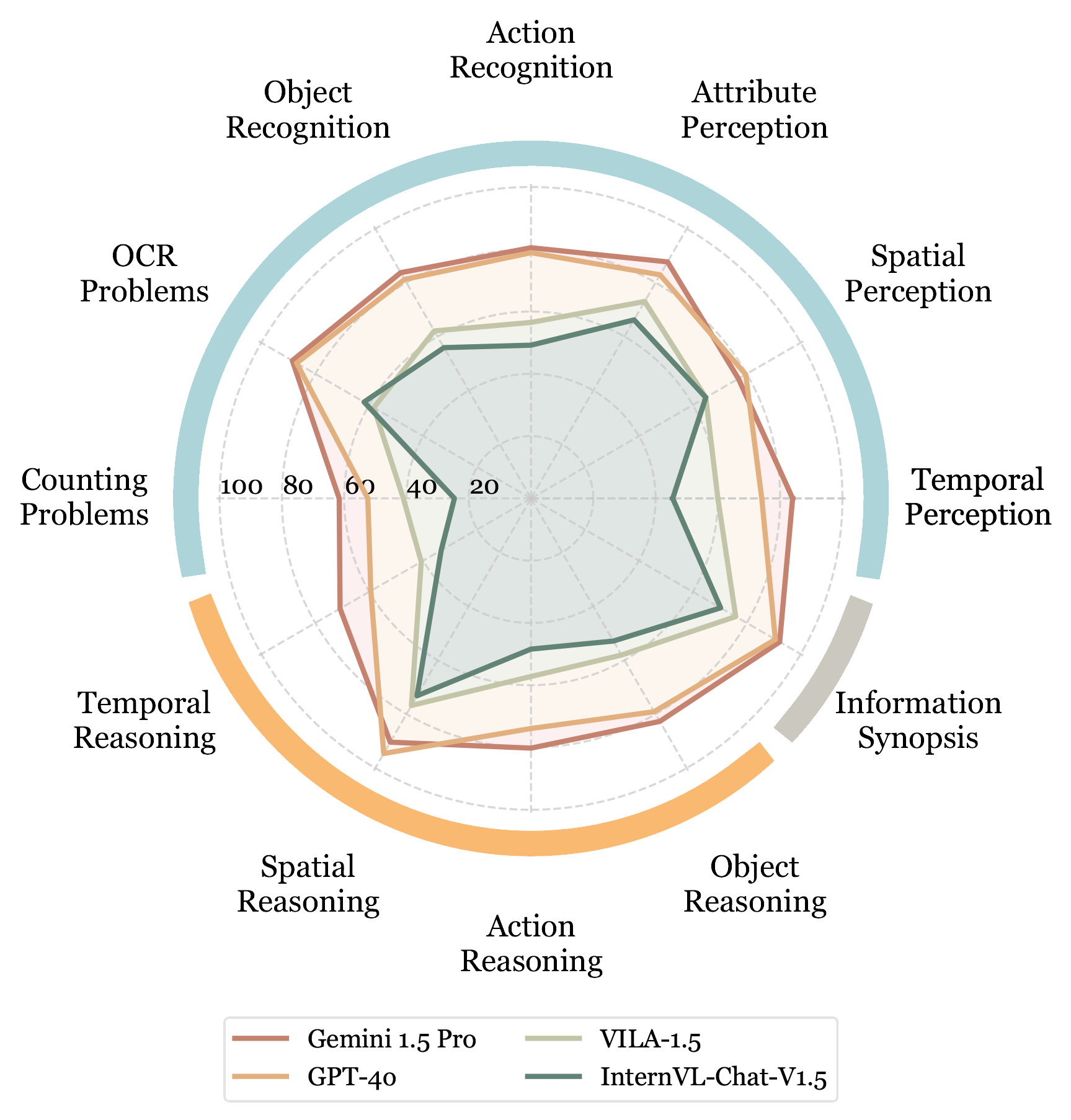
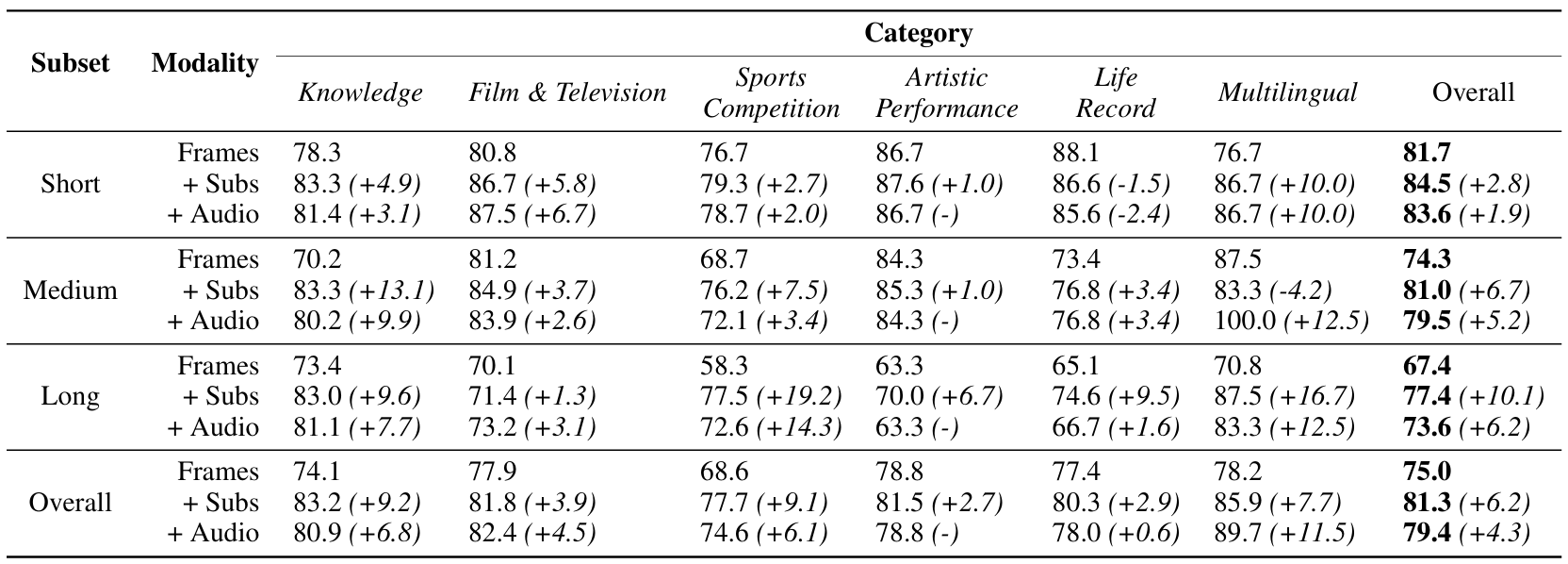
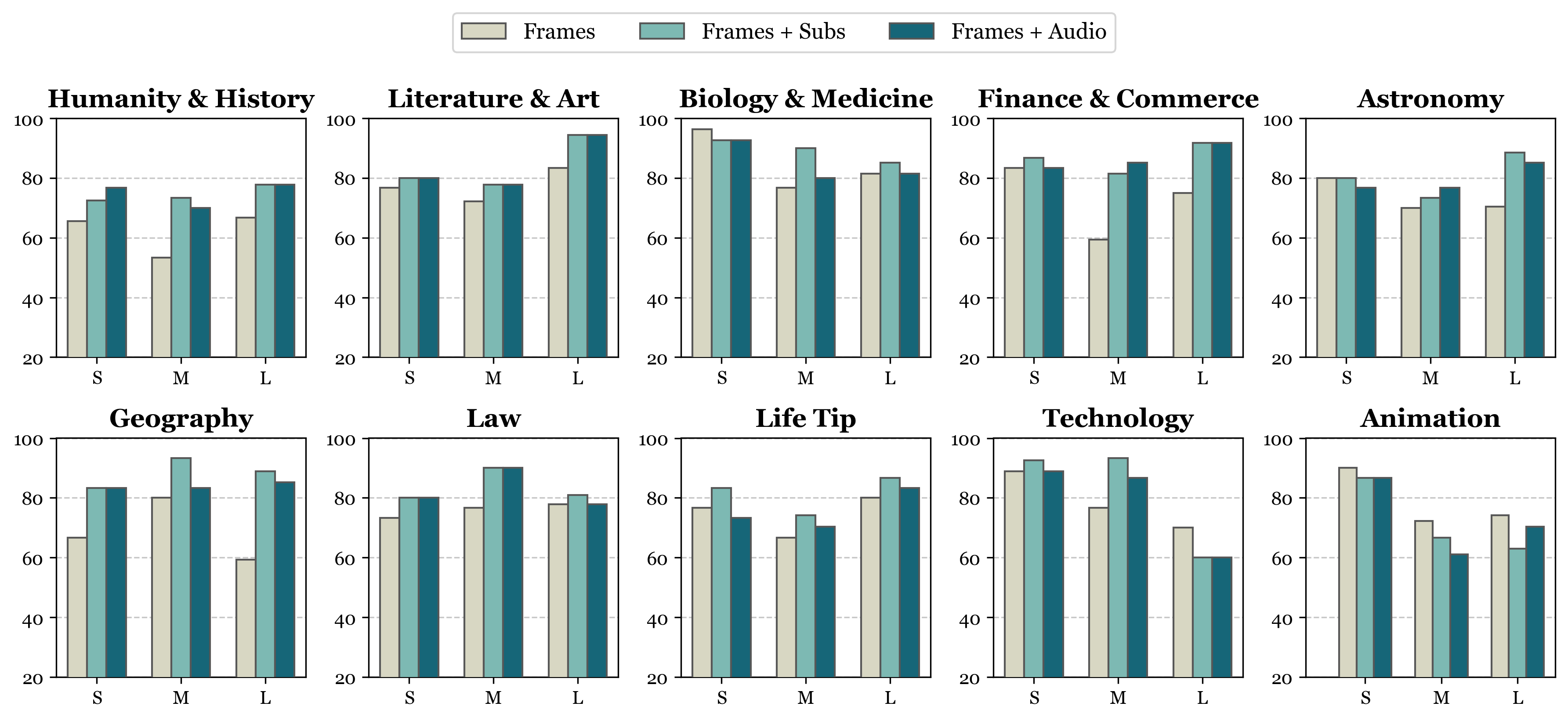
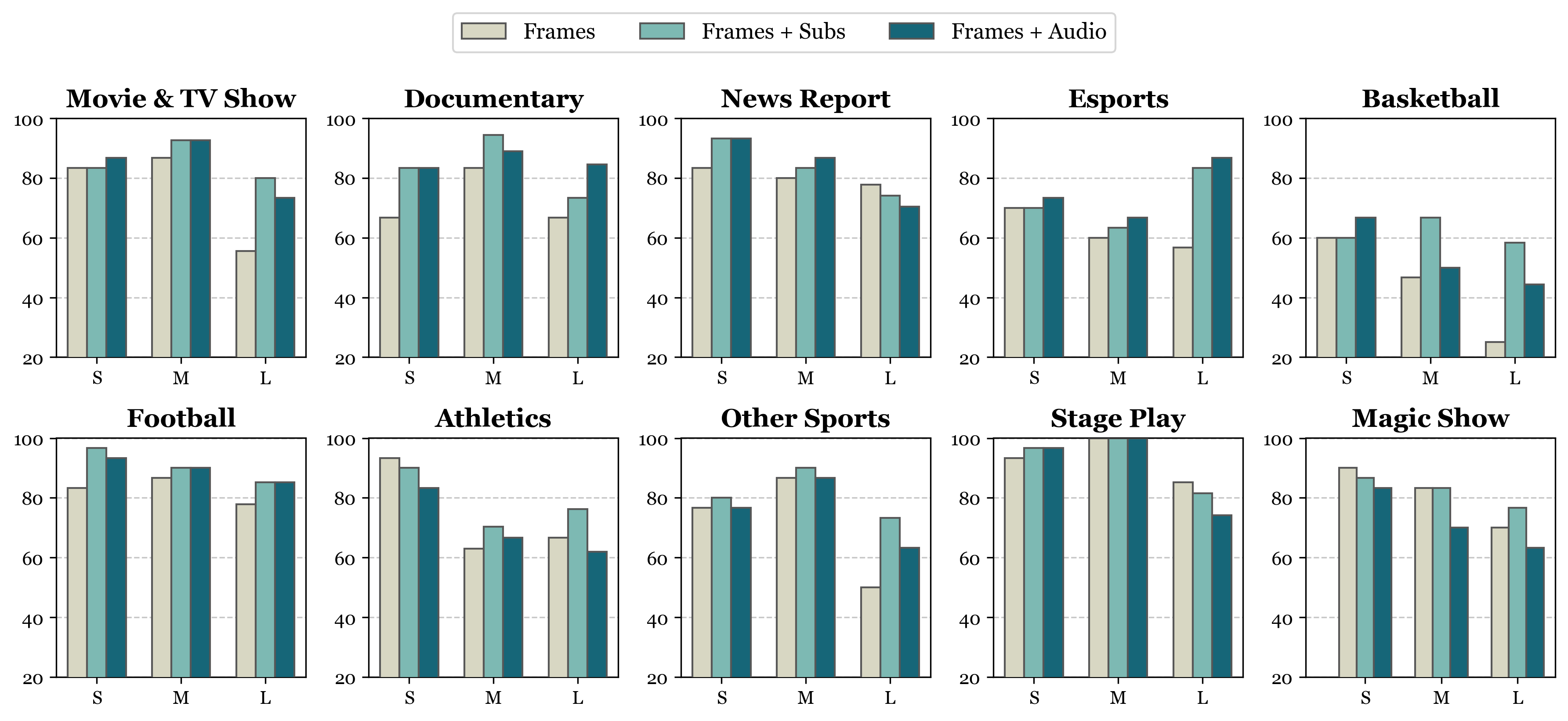
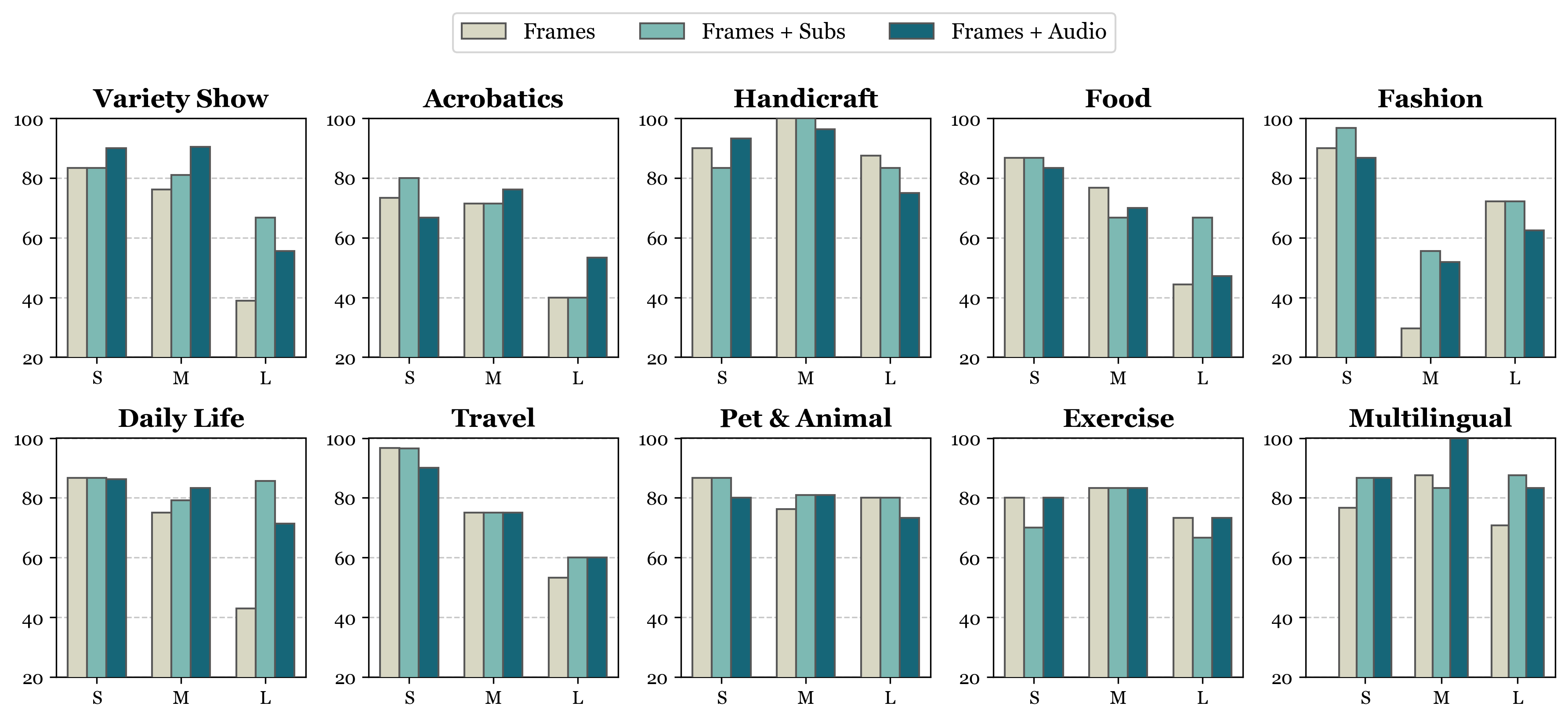
Accuracy scores on Video-MME are presented for short, medium, and long videos, taking the corresponding subtitles as input or not.
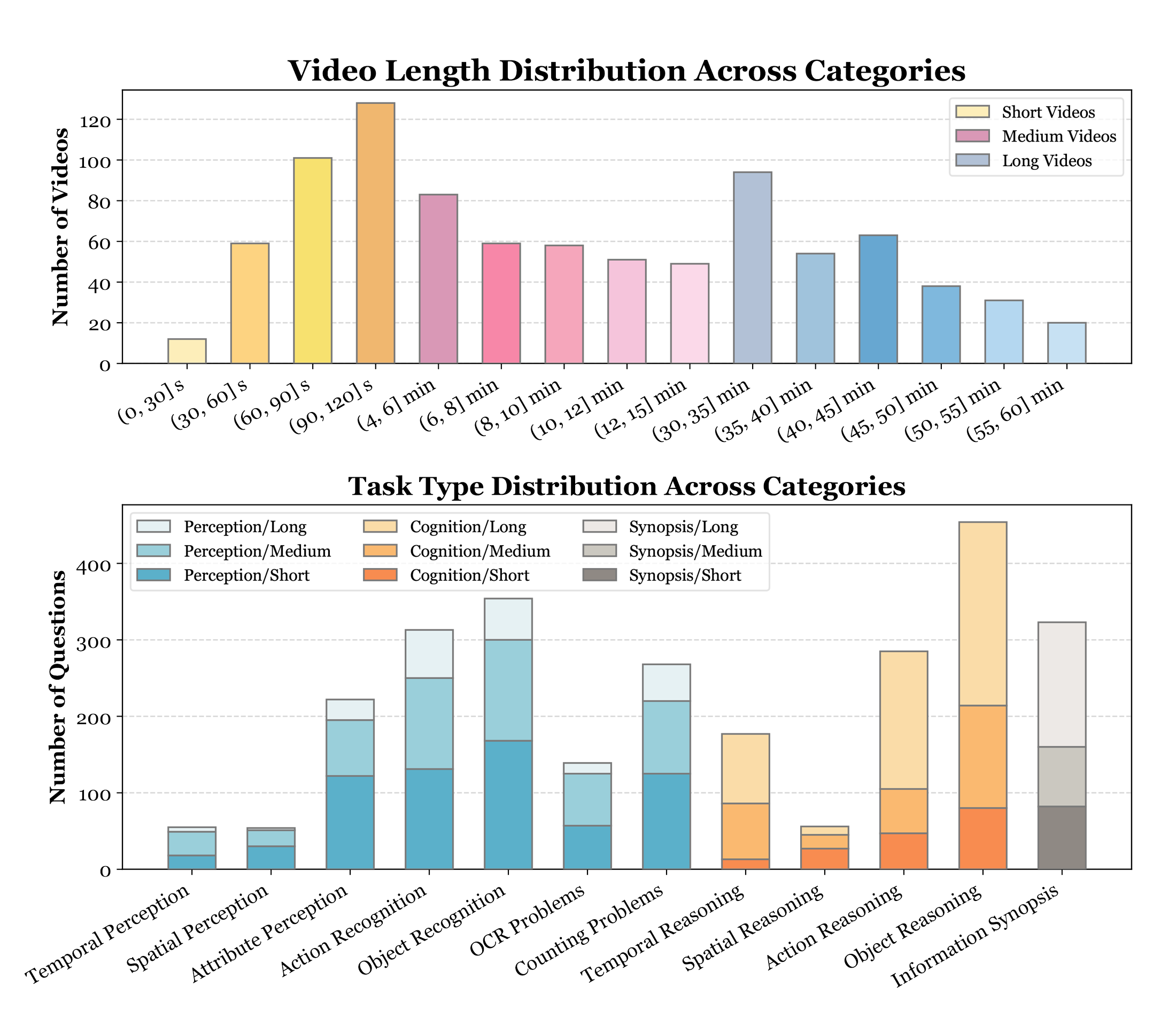
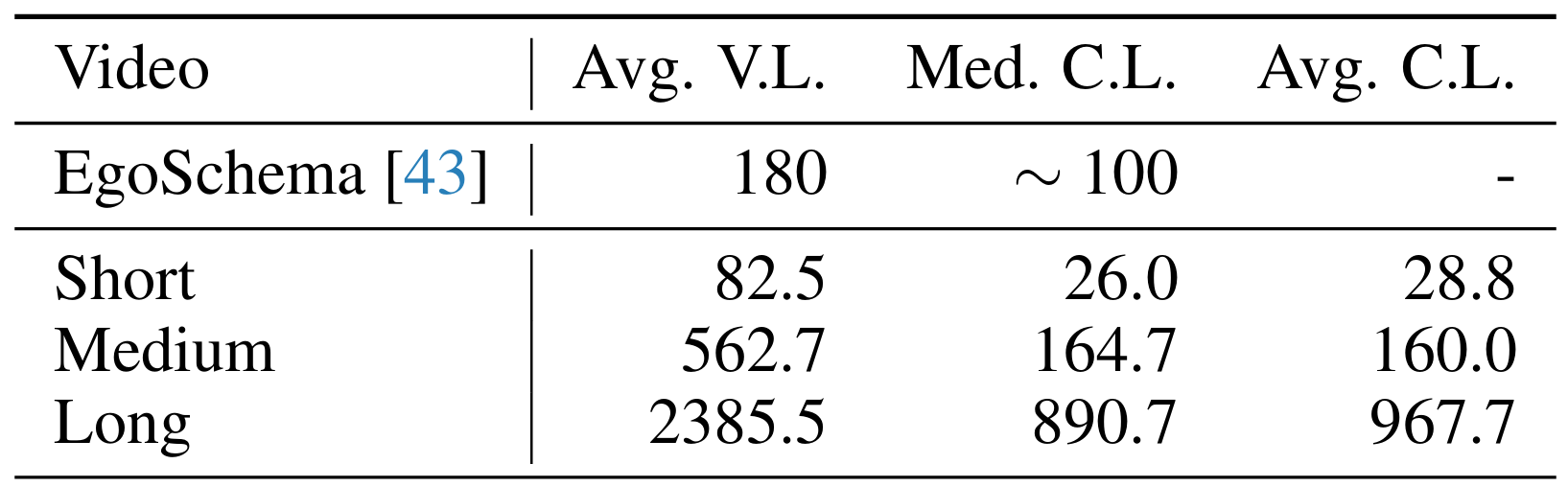
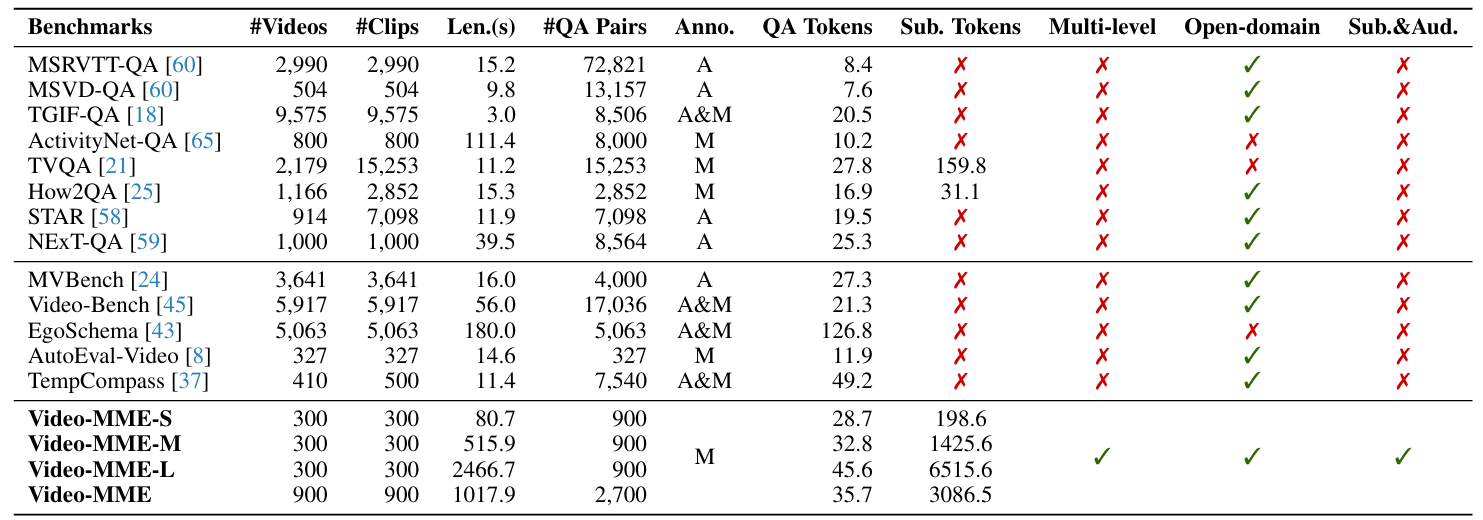
Short Video: < 2min Medium Video: 4min ~ 15min Long Video: 30min ~ 60min
By default, this leaderboard is sorted by results with subtitles. To view other sorted results, please click on the corresponding cell.
| # | Model | LLM Params |
Frames | Date | Overall (%) | Short Video (%) | Medium Video (%) | Long Video (%) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| w/o subs | w subs | w/o subs | w subs | w/o subs | w subs | w/o subs | w subs | |||||
|
video-SALMONN 2+
THU & ByteDance |
72B | 10 fps 6* | 2025-09-28 | 79.7 | 81.6 | 85.0 | 85.4 | 81.7 | 83.0 | 72.3 | 76.4 | |
|
Gemini 1.5 Pro
|
- | 1/0.5 fps1* | 2024-06-15 | 75.0 | 81.3 | 81.7 | 84.5 | 74.3 | 81.0 | 67.4 | 77.4 | |
|
AdaReTaKe
HIT & Huawei |
72B | 1024 | 2025-03-04 | 73.5 | 79.6 | 80.6 | 82.8 | 74.9 | 79.7 | 65.0 | 76.4 | |
|
JT-VL-Chat
China Mobile |
38B | 1800 | 2025-07-24 | 70.6 | 79.1 | 81.6 | 84.3 | 68.6 | 76.9 | 61.6 | 76.1 | |
| Qwen2-VL
Alibaba |
72B | 7683* | 2024-08-19 | 71.2 | 77.8 | 80.1 | 82.2 | 71.3 | 76.8 | 62.2 | 74.3 | |
| GPT-4o
OpenAI |
- | 3842* | 2024-06-15 | 71.9 | 77.2 | 80.0 | 82.8 | 70.3 | 76.6 | 65.3 | 72.1 | |
| LLaVA-Video
Bytedance & NTU S-Lab |
72B | 64 | 2024-08-28 | 70.6 | 76.9 | 81.4 | 82.8 | 68.9 | 75.6 | 61.5 | 72.5 | |
|
Gemini 1.5 Flash
|
- | 1/0.5 fps1* | 2024-06-15 | 70.3 | 75.0 | 78.8 | 79.8 | 68.8 | 74.7 | 61.1 | 68.8 | |
| Oryx-1.5
THU & Tencent & NTU |
34B | 128 | 2024-10-21 | 67.3 | 74.9 | 77.3 | 80.6 | 65.3 | 74.3 | 59.3 | 69.9 | |
|
InternVL2.5
Shanghai AI Lab |
72B | 64 | 2024-12-13 | 72.1 | 74.0 | 82.8 | 83.2 | 70.9 | 74.1 | 62.6 | 64.8 | |
|
Keye-VL-1.5
Kwai Keye Team |
8B | 64 | 2025-08-29 | 73.0 | 74.0 | 81.2 | 84.0 | 70.7 | 71.9 | 67.1 | 66.2 | |
|
TSPO
XJTU & TeleAI & USTB |
72B | 128 | 2025-09-22 | 73.0 | 73.7 | 81.3 | 83.4 | 73.6 | 74.2 | 64.0 | 63.6 | |
|
ViLAMP
RUC & Ant Group |
7B | 1 fps4* | 2025-04-02 | 67.5 | 73.5 | 78.9 | 81.2 | 65.8 | 71.2 | 57.8 | 68.1 | |
|
Aria
Rhymes AI |
8x3.5B | 256 | 2024-10-11 | 67.6 | 72.1 | 76.9 | 78.3 | 67.0 | 71.7 | 58.8 | 66.3 | |
|
Long-VITA
Tencent & NJU |
14B | 1 fps 7* | 2025-07-23 | 67.0 | 72.0 | 75.0 | 77.0 | 66.0 | 73.0 | 59.0 | 66.0 | |
|
LinVT
Meituan Inc |
7B | 120 | 2025-02-05 | 70.3 | 71.7 | 79.0 | 80.1 | 71.6 | 68.7 | 63.2 | 63.3 | |
|
TPO
Stanford University |
7B | 96 | 2025-01-26 | 65.6 | 71.5 | 76.8 | 78.7 | 64.6 | 69.4 | 55.4 | 66.4 | |
| VideoLLaMA 3
Alibaba |
7B | 180 | 2025-01-24 | 66.2 | 70.3 | 80.1 | 80.2 | 63.7 | 69.6 | 54.9 | 61.0 | |
| LiveCC
NUS Show Lab & ByteDance |
7B | 2 fps5* | 2025-04-26 | 64.1 | 70.3 | 74.8 | 76.6 | 63.9 | 70.3 | 53.7 | 64.1 | |
| QuoTA
XMU |
7B | 64 | 2025-03-04 | 65.9 | 70.0 | 77.1 | 79.0 | 64.9 | 68.0 | 55.7 | 62.9 | |
| NVILA
NVIDIA |
7B | 1024 | 2024-11-06 | 64.2 | 70.0 | 75.7 | 77.6 | 62.2 | 69.0 | 54.8 | 63.3 | |
|
VideoChat-Flash
Shanghai AI Lab & NJU |
7B | 512 | 2025-02-06 | 65.3 | 69.7 | 78.0 | 76.6 | 67.8 | 63.8 | 55.6 | 63.3 | |
|
LLaVA-OneVision
Bytedance & NTU S-Lab |
72B | 32 | 2024-08-08 | 66.3 | 69.6 | 76.7 | 79.3 | 62.2 | 66.9 | 60.0 | 62.4 | |
| GPT-4o mini
OpenAI |
- | 250 | 2024-07-21 | 64.8 | 68.9 | 72.5 | 74.9 | 63.1 | 68.3 | 58.6 | 63.4 | |
|
ReTaKe
HIT & Huawei |
7B | 1024 | 2025-02-05 | 63.9 | 68.9 | 72.8 | 74.3 | 62.9 | 69.3 | 56.0 | 62.9 | |
| ByteVideoLLM
Bytedance |
14B | 100 | 2024-10-21 | 64.6 | 68.8 | 74.4 | 77.1 | 62.9 | 69.1 | 56.4 | 60.2 | |
| mPLUG-Owl3
Alibaba |
7B | 128 | 2024-11-13 | 59.3 | 68.1 | 70.0 | 72.8 | 57.7 | 66.9 | 50.1 | 64.5 | |
| MiniCPM-o 2.6
OpenBMB |
8B | 64 | 2025-01-16 | 63.9 | 67.9 | 75.4 | 78.3 | 63.9 | 69.1 | 52.2 | 56.3 | |
| VideoLLaMA 2
Alibaba |
72B | 32 | 2024-08-29 | 62.4 | 64.7 | 69.8 | 72.0 | 59.9 | 63.0 | 57.6 | 59.0 | |
| MiniCPM-V 2.6
OpenBMB |
8B | 64 | 2024-08-12 | 60.9 | 63.7 | 71.3 | 73.5 | 59.4 | 61.1 | 51.8 | 56.3 | |
| GPT-4V
OpenAI |
- | 10 | 2024-06-15 | 59.9 | 63.3 | 70.5 | 73.2 | 55.8 | 59.7 | 53.5 | 56.9 | |
| Claude 3.5 Sonnet
Anthropic |
- | 20 | 2024-07-30 | 60.0 | 62.9 | 71.0 | 73.5 | 57.4 | 60.1 | 51.2 | 54.7 | |
|
TimeMarker
Meituan |
8B | 128 | 2024-11-07 | 57.3 | 62.8 | 71.0 | 75.8 | 54.4 | 60.7 | 46.4 | 51.9 | |
| InternVL2
Shanghai AI Lab |
34B | 16 | 2024-07-18 | 61.2 | 62.4 | 72.0 | 72.8 | 59.1 | 61.3 | 52.6 | 53.0 | |
| Video-XL
SJTU & BAAI |
7B | 128 | 2024-10-24 | 55.5 | 61.0 | 64.0 | 67.4 | 53.2 | 60.7 | 49.2 | 54.9 | |
| VITA
Tencent Youtu Lab & NJU |
8×7B | 32 | 2024-09-08 | 55.8 | 59.2 | 65.9 | 70.4 | 52.9 | 56.2 | 48.6 | 50.9 | |
| VITA 1.5
Tencent Youtu Lab & NJU |
7B | 16 | 2025-01-22 | 56.1 | 58.7 | 67.0 | 69.9 | 54.2 | 55.7 | 47.1 | 50.4 | |
| Kangaroo
Meituan & UCAS |
8B | 64 | 2024-07-23 | 56.0 | 57.6 | 66.1 | 68.0 | 55.3 | 55.4 | 46.6 | 49.3 | |
| Video-CCAM
QQMM |
14B | 96 | 2024-07-16 | 53.2 | 57.4 | 62.2 | 66.0 | 50.6 | 56.3 | 46.7 | 49.9 | |
| Long-LLaVA
Amazon |
7B | 64 | 2024-09-09 | 52.9 | 57.1 | 61.9 | 66.2 | 51.4 | 54.7 | 45.4 | 50.3 | |
| LongVA
NTU S-Lab |
7B | 128 | 2024-06-25 | 52.6 | 54.3 | 61.1 | 61.6 | 50.4 | 53.6 | 46.2 | 47.6 | |
| InternVL-Chat-V1.5
Shanghai AI Lab |
20B | 10 | 2024-06-15 | 50.7 | 52.4 | 60.2 | 61.7 | 46.4 | 49.1 | 45.6 | 46.6 | |
| Qwen-VL-Max
Alibaba |
- | 4 | 2024-06-15 | 51.3 | 51.2 | 55.8 | 57.6 | 49.2 | 48.9 | 48.9 | 47.0 | |
| ShareGemini
XMU |
7B | 64 | 2024-06-20 | 43.2 | 47.9 | 49.1 | 52.8 | 41.3 | 47.3 | 39.1 | 43.4 | |
| SliME
CASIA |
8B | 8 | 2024-07-16 | 45.3 | 47.2 | 53.3 | 55.4 | 42.7 | 44.4 | 39.8 | 41.7 | |
| Chat-UniVi-v1.5
PKU |
7B | 64 | 2024-06-15 | 40.6 | 45.9 | 45.7 | 51.2 | 40.3 | 44.6 | 35.8 | 41.8 | |
| VideoChat2-Mistral
Shanghai AI Lab |
7B | 16 | 2024-06-15 | 39.5 | 43.8 | 48.3 | 52.8 | 37.0 | 39.4 | 33.2 | 39.2 | |
| ShareGPT4Video
Shanghai AI Lab |
8B | 16 | 2024-06-17 | 39.9 | 43.6 | 48.3 | 53.6 | 36.3 | 39.3 | 35.0 | 37.9 | |
| ST-LLM
PKU |
7B | 64 | 2024-06-15 | 37.9 | 42.3 | 45.7 | 48.4 | 36.8 | 41.4 | 31.3 | 36.9 | |
| Qwen-VL-Chat
Alibaba |
7B | 4 | 2024-06-15 | 41.1 | 41.9 | 46.9 | 47.3 | 38.7 | 40.4 | 37.8 | 37.9 | |
| Video-LLaVA
PKU |
7B | 8 | 2024-06-15 | 39.9 | 41.6 | 45.3 | 46.1 | 38.0 | 40.7 | 36.2 | 38.1 | |
Green date indicates the newly added/updated models - indicates closed-source models
1* The short and medium videos are sampled at 1 fps, while the long videos are sampled at 0.5 fps to ensure the stability of the API. 2* The videos less than 384 seconds are sampled at 1 fps, and for those longer than 384 seconds, we extract 384 frames uniformly. All the frames are resized to 512x512 resolution to fit within GPT-4o’s max context length. 3* The videos are sampled at 2 fps, and the upper limit is 768 frames. 4* The videos are sampled at 1 fps, and the upper limit is 600 frames. 5* The videos are sampled at 2 fps, and the upper limit is 480 frames. 6* The videos are sampled at 10 fps, and the upper limit is 768 frames. 7* The videos are sampled at 1 fps, and the upper limit is 256 frames.